
神经网络 —— 智能背后的神秘力量


在当今这个科技飞速发展的时代,神经网络无疑是最炙手可热的话题之一。从智能手机的语音助手,到自动驾驶汽车的智能导航;从医疗领域的疾病诊断,再到金融行业的风险预测,神经网络的身影无处不在,悄然改变着我们的生活方式,推动着社会的智能化进程。
你是否好奇,神经网络究竟是什么 “神奇魔法”,能赋予机器如此强大的智能?今天,就让我们一同揭开它神秘的面纱,探寻智能背后的力量源泉。
一、神经网络初印象
神经网络,简而言之,是一种模仿人类大脑神经元结构与工作方式的数学模型。就像我们的大脑由数以亿计的神经元相互连接构成,神经网络同样由大量的节点(神经元)以及它们之间的连接组成。每个神经元都像是一个小小的 “信息处理器”,它们接收来自其他神经元的信号,经过一系列复杂的计算后,再将结果传递给下一个神经元。如此层层递进,最终实现对输入信息的深度处理与理解。
二、解构神经网络

(一)神经元 —— 基本单元
神经元作为神经网络的基本单元,就如同构成大厦的基石般关键。每个神经元都承担着接收、处理与传递信息的重任。它从多个上游神经元接收电信号,这些信号就像是一封封 “信件”,携带了不同的信息。神经元收到后,会根据自身内部设定的规则,对这些信号进行加权求和,就好像把信件中的重要内容提取出来,整理归类。之后,再经过一个特殊的 “处理器”—— 激活函数,将整理后的结果转化为新的信号,传递给下游神经元。这种工作模式与生物神经元极为相似,生物神经元通过树突接收来自其他神经元的电化学信号,在细胞体内整合处理,随后通过轴突将信号传递出去,从而实现大脑中信息的流转与处理。
(二)层次架构
神经网络通常由输入层、隐藏层以及输出层三个部分构成。输入层宛如一扇敞开的大门,负责接收来自外界的各类数据,无论是图像的像素值、文本的字符编码,还是声音的频谱特征,都能被它吸纳进来,是信息进入神经网络的起点。隐藏层则如同神秘的 “加工厂”,位于输入层与输出层之间,它的神经元数量与层数可以根据任务的复杂程度灵活调整。简单任务或许只需一层隐藏层,而处理复杂如人脸识别、自然语言翻译等任务时,就需要多层隐藏层相互协作。这些隐藏层的神经元们各司其职,对输入数据进行层层转换、抽象,挖掘其中深层次的特征与模式,是神经网络实现强大功能的关键所在。输出层则像一位 “发言人”,它根据隐藏层传来的信息,生成最终的结果,这个结果可能是图像分类的类别标签、股价预测的数值,又或是机器翻译后的文本内容,是神经网络对外展示其智能决策的窗口。
(三)权重与偏置 ——“幕后操控手”
权重与偏置堪称神经元中的 “幕后操控手”,对神经元的输出起着决定性作用。权重如同连接神经元之间的 “桥梁强度”,它决定了上游神经元传递过来的信息对当前神经元影响的大小。打个比方,如果权重较大,就意味着上游神经元传来的信息备受重视,对当前神经元的输出有着显著的拉动作用;反之,若权重较小,其影响则相对微弱。而偏置则像是神经元的 “内在倾向”,它为神经元提供了一个基础的输出值,即使所有输入信号都为零,偏置也能让神经元保持一定的活跃度,避免输出陷入死寂。在神经网络的训练过程中,权重与偏置会通过反向传播算法不断优化调整,就如同投篮训练,一开始运动员(神经网络)的投篮姿势(权重与偏置)可能并不标准,命中率(输出结果准确性)较低,但随着不断尝试,观察每次投篮的偏差(损失函数),逐渐调整姿势,最终实现高命中率,让神经网络能够精准地对输入数据做出正确反应。
(四)激活函数 —— 引入 “非线性魔法”
如果说权重与偏置赋予了神经元基础的调节能力,那么激活函数则为神经网络带来了 “非线性魔法”。倘若没有激活函数,无论神经网络有多少层,其本质都只是对输入数据进行线性变换,这就好比用一把直尺去丈量世间万物,面对复杂的曲线、曲面问题便束手无策。而激活函数的加入,打破了这种线性局限,它能够将神经元的输入映射为非线性的输出,使得神经网络拥有了拟合任意复杂函数的潜力。常见的激活函数有 Sigmoid、ReLU、Tanh 等。Sigmoid 函数能将输入值压缩至 0 到 1 之间,常用于二分类问题,输出可直接视作某一类别的概率;ReLU 函数则简单粗暴,对正数输入原样输出,负数输入直接归零,因其计算高效、能有效缓解梯度消失问题,在深层神经网络中备受青睐;Tanh 函数输出范围在 -1 到 1 之间,零点对称,相比 Sigmoid 函数,在某些场景下能更好地平衡正负输入的影响,收敛速度也更快。这些激活函数各具特色,为神经网络应对不同任务需求提供了多样的工具选择。
三、神经网络的 “学习秘籍”
(一)前向传播 —— 数据的奇幻旅程
前向传播,恰似一场数据的奇幻旅程。当输入数据踏入神经网络的大门 —— 输入层后,便开启了层层闯关模式。在每一层中,数据与神经元的权重、偏置相互作用,通过加权求和得到初步结果,再经由激活函数的 “魔法加工”,转化为更具表现力的信息,继续向下一层传递。如此循环往复,数据如同携带秘密情报的信使,在神经元之间穿梭,每经过一层,就被提炼、升华一次,最终抵达输出层,输出层根据这些历经磨砺的数据,给出一个预测结果。这就好比我们根据一个人的外貌特征(输入数据),经过大脑不同区域(隐藏层)的分析,最终判断出他的职业(输出结果)。整个过程一气呵成,是神经网络发挥作用的直接体现。
(二)反向传播 —— 误差的逆向修正
如果说前向传播是冲锋陷阵的先锋,那么反向传播则是默默耕耘的后勤保障。当输出层输出预测结果后,这个结果与真实值之间往往存在一定的误差,就像射箭偏离了靶心。此时,反向传播机制启动,它如同一位严谨的纠错大师,依据输出误差,沿着与前向传播相反的路径,逆向逐层回溯。在回溯过程中,根据误差的大小,运用链式法则,精准计算出每个神经元权重与偏置对误差的 “贡献” 程度,进而对它们进行相应的调整,使得下一次前向传播时,预测结果能更接近真实值。这就好比射箭手通过观察每次射箭与靶心的偏差,回过头来调整自己的姿势、力度(权重与偏置),以期下次命中目标。通过不断地重复前向传播与反向传播,神经网络如同一个不断自我磨砺的剑客,逐渐提升自己的技艺,让预测结果愈发精准。
(三)训练中的 “火候” 掌控
在神经网络的训练过程中,有两个关键的 “火候” 参数需要精心调控,那就是训练轮数(Epoch)和学习率(Learning Rate)。训练轮数决定了神经网络对数据的学习次数,就如同学生做练习题,做的次数越多,对知识点的掌握可能就越牢固。但并非训练轮数越多越好,如果过度训练,神经网络可能会陷入 “死记硬背” 的困境,将数据中的噪声也一并学习,导致在面对新数据时,泛化能力大打折扣,出现过拟合现象。反之,若训练轮数过少,神经网络还未充分学习到数据的特征与规律,又会出现欠拟合的情况,如同学生对知识一知半解,考试时无法应对各种题型。
学习率则像是学生学习时的步长,它控制着每次权重与偏置更新的幅度。较大的学习率能让神经网络在训练初期快速前进,迅速调整参数,就像大步奔跑,能快速探索知识的大致领域;但到了训练后期,接近最优解时,如果学习率依旧很大,就可能会像脱缰的野马,在最优解附近来回震荡,甚至错过最优解,导致无法收敛。而较小的学习率虽然能保证在最优解附近稳步微调,如同小碎步前行,精细打磨知识细节,但学习速度会变得极为缓慢,还容易陷入局部最优解的泥沼,耗费大量的训练时间。因此,合理设置训练轮数与学习率,是神经网络训练成功的关键,需要根据具体任务和数据特点,反复试验、精细调整,方能让神经网络达到最佳性能状态。
四、神经网络的 “超能力” 实战
(一)图像识别 ——“火眼金睛” 辨万物
图像识别,堪称神经网络的一项 “看家本领”。在安防领域,基于神经网络的监控系统宛如一位不知疲倦的 “卫士”,能够实时分析监控画面,精准识别出人脸、车辆以及异常行为。无论是在人头攒动的车站、机场,还是车水马龙的街道,它都能迅速锁定目标,为公共安全保驾护航。在医疗行业,神经网络助力医生解读 X 光、CT、MRI 等医学影像,如同为医生增添了一双 “透视眼”,能够敏锐地发现病灶,辅助疾病的早期诊断,大大提高诊断效率与准确性,为患者争取宝贵的治疗时间。于交通出行而言,它更是自动驾驶技术的核心支撑,让汽车能够精准识别道路标识、车辆与行人,实现智能导航与驾驶决策,引领我们迈向安全、便捷的出行新时代。
而这一强大功能的背后,离不开诸多经典网络架构的支撑。卷积神经网络(CNN)便是其中的佼佼者,它通过卷积层、池化层与全连接层的巧妙协作,能够自动提取图像的深层特征。就像一个经验丰富的画师,能精准捕捉画面中的线条、纹理、形状等关键信息,将复杂的图像转化为简洁而富有代表性的特征向量,进而实现高效分类识别。从早期的 LeNet 到如今的 ResNet、EfficientNet 等,这些不断演进的 CNN 架构在图像识别的舞台上大放异彩,持续刷新着识别精度的纪录,推动着图像识别技术向更高水平迈进。
(二)自然语言处理 —— 搭建人机沟通 “桥梁”
自然语言处理(NLP),旨在让计算机理解并生成人类语言,是神经网络构建人机沟通 “桥梁” 的关键所在。在机器翻译领域,神经网络打破了语言之间的壁垒,实现近乎实时的文本翻译,让全球信息交流畅通无阻。如今,借助神经网络翻译工具,我们阅读外文文献、浏览国际资讯变得轻松便捷,不同国家和地区的人们能够跨越语言鸿沟,紧密相连。文本分类也是 NLP 的重要应用之一,面对海量的新闻资讯、社交媒体帖子,神经网络能够依据内容快速分类,精准推送我们感兴趣的信息,节省信息筛选的时间成本。
以智能客服为例,它已成为众多企业提升服务质量与效率的得力助手。无论是解答产品咨询、处理售后问题,还是应对日常闲聊,智能客服依托神经网络技术,瞬间理解用户问题,并迅速给出准确回复。这背后是词嵌入、循环神经网络(RNN)、Transformer 等技术的协同发力。词嵌入将单词映射为高维向量,挖掘语义关联;RNN 及其变体(如 LSTM、GRU)擅长处理序列信息,捕捉语句中的逻辑脉络;Transformer 则凭借强大的多头自注意力机制,让模型能聚焦文本关键部分,实现对语义的深度理解,从而为用户提供流畅、智能的交互体验。
(三)语音识别 —— 让机器 “听懂” 世界
语音识别技术赋予了机器 “倾听” 与理解人类语音的能力,彻底改变了人机交互的方式。其原理基于对声音信号的分帧处理,将连续的语音流切割为小段,再从中提取梅尔频率倒谱系数(MFCC)等特征,这些特征如同语音的 “指纹”,承载着语音的关键信息。随后,通过深度神经网络(DNN)、长短时记忆网络(LSTM)等模型对这些特征进行学习与识别,将语音信号转化为文本。
在日常生活中,语音识别的应用场景随处可见。智能语音助手如苹果的 Siri、亚马逊的 Alexa、小米的小爱同学等,已然成为人们生活中的贴心伙伴。只需轻声呼唤,它们便能帮忙查询天气、播放音乐、设置提醒,让双手得以解放,生活更加便捷。在会议记录、课堂笔记等场景中,语音识别技术也大显身手,能够实时将语音转换为文字,不仅提高记录效率,还便于后续整理与检索,为学习与工作带来极大便利。随着 5G 等技术的普及,语音识别与更多领域融合创新,正不断拓展着人机交互的边界,让机器愈发 “善解人意”,融入生活的方方面面。
五、深度学习框架 —— 神经网络的 “魔法工坊”
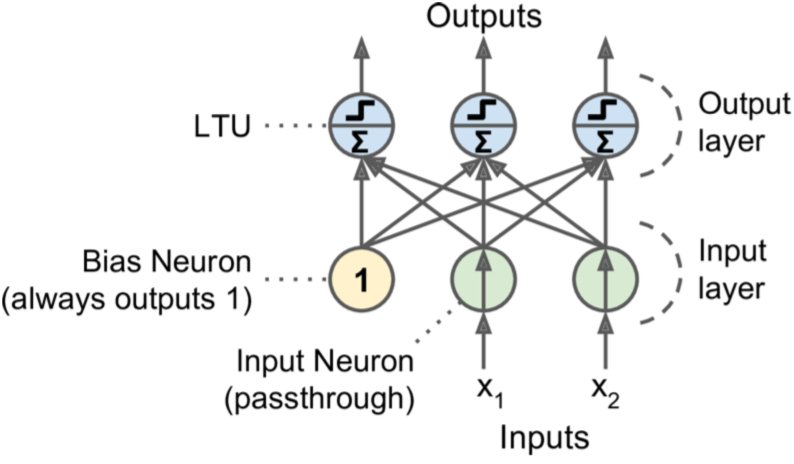
了解了神经网络的基本原理与实战应用后,你或许会好奇,如何才能便捷地搭建这些复杂精妙的神经网络呢?这就不得不提到深度学习框架了,它们宛如一个个功能强大的 “魔法工坊”,为神经网络的构建与训练提供了极大的便利。
TensorFlow,作为深度学习领域的老牌劲旅,由谷歌大脑团队精心打造并开源。它以灵活的计算图为核心特色,能够将复杂的计算流程直观地展现为节点与边交织的图结构,让使用者在模型搭建时犹如搭建积木一般,轻松构建出复杂的神经网络架构。自动微分功能更是其一大亮点,如同一位贴心的数学助手,自动计算模型梯度,为各种优化算法的实施铺平道路,大大减轻了开发者手动推导梯度的繁重负担。同时,TensorFlow 对多种硬件和操作系统的广泛支持,使其宛如一位 “全能选手”,无论是在服务器端的大规模训练,还是移动端的轻量化部署,都能游刃有余,展现出卓越的性能表现。
PyTorch,则是近年来迅速崛起的后起之秀,由 Facebook 的人工智能研究小组研发。它凭借动态计算图技术独树一帜,让神经网络的搭建过程充满了灵活性与交互性,开发者可以在运行时随心所欲地调整模型结构,就像一位自由创作的艺术家,随时根据灵感优化作品,极大地提高了实验效率与调试便利性。简洁明了的 API 设计,使其上手难度直线降低,即使是深度学习领域的新手,也能快速掌握,开启自己的神经网络探索之旅。而且,PyTorch 活跃且强大的社区支持,为开发者提供了源源不断的学习资源、教程以及各种预训练模型,仿佛一个温暖的大家庭,大家在这里分享经验、共同成长,推动着 PyTorch 在学术研究与工业应用中不断前行。
这些深度学习框架的出现,无疑为神经网络的发展注入了强大动力,让更多人能够投身于人工智能的创新浪潮之中,共同探索智能世界的无限可能。
六、神经网络的未来蓝图
展望未来,神经网络的发展前景宛如一片浩瀚无垠、充满无限可能的星辰大海。随着科技的持续进步,我们有理由相信,神经网络将在更多未知领域实现重大突破,为人类社会带来更为深刻、广泛的变革。
一方面,神经网络有望在医疗保健领域取得更为瞩目的成就。通过对海量医疗数据的深度挖掘与精准分析,它能够助力医生实现疾病的早期精准诊断,为患者提供个性化、高效的治疗方案。不仅如此,在药物研发过程中,神经网络还可以模拟药物分子与人体细胞的相互作用,极大地加速新药研发进程,降低研发成本,让更多创新药物更快地惠及患者。
在应对气候变化这一全球性挑战方面,神经网络同样潜力巨大。它能够对气象数据、地理信息以及能源消耗等复杂数据进行实时监测与综合分析,为我们提供更为精准的气候预测,助力制定科学合理的节能减排策略,推动可持续能源的开发与利用,为地球家园的绿色未来贡献力量。
然而,我们也必须清醒地认识到,神经网络在迈向未来的征程中,仍面临诸多亟待攻克的难题。其中,模型的可解释性问题尤为突出,宛如一团笼罩在神经网络上空的迷雾。由于其内部结构复杂、决策过程高度抽象,使得人们难以洞悉其背后的逻辑与依据,这在诸如医疗、金融等对决策透明度要求极高的领域,无疑成为了阻碍其广泛应用的关键因素。
为了驱散这团迷雾,研究人员正全力以赴,试图通过可视化技术、特征归因方法等多种途径,揭开神经网络决策的神秘面纱,让其运行机制清晰透明,从而赢得人们的信任与认可。
与此同时,随着物联网时代的全面来临,数据呈爆炸式增长,如何在资源受限的边缘设备上高效运行神经网络,也成为了当下的紧迫挑战。针对这一问题,研究人员正积极探索轻量化网络架构、模型压缩算法以及专为边缘计算设计的硬件加速器,力求让神经网络在各类终端设备上都能流畅运行,实现智能化无处不在的美好愿景。
值得期待的是,随着量子计算技术的逐步成熟,神经网络将迎来全新的发展契机。量子计算凭借其超强的计算能力,有望大幅缩短神经网络的训练时间,使其能够处理更为复杂、庞大的数据集,解锁前所未有的智能潜能,为解决诸多世界级难题开辟崭新道路。
神经网络作为当今时代最具活力与创造力的技术之一,已然深刻改变了我们的生活轨迹,并将继续引领我们奔赴更加智能、美好的未来。尽管前方荆棘丛生,但在全球科研人员的共同努力下,相信神经网络必将攻克重重难关,绽放出更加绚烂夺目的光芒,为人类社会的进步书写更加辉煌壮丽的篇章。让我们怀揣期待,共同见证这一伟大变革的到来!
七、结语
神经网络,这一源于对人类大脑模仿的智慧结晶,已然跨越了理论的边界,深深嵌入到我们生活的每一处细微角落。从日常琐事的便捷处理,到关乎人类未来发展的重大领域探索,它都展现出了无与伦比的价值与潜力。
回顾我们一同走过的探索之旅,从揭开神经元的神秘面纱,到洞悉神经网络架构的精妙设计;从掌握其学习与训练的核心秘籍,再到领略它在多领域的 “超能力” 实战风采,以及借助深度学习框架搭建起属于自己的智能模型,每一步都见证了人类智慧与科技力量的完美融合。
展望未来,神经网络前进的道路虽布满荆棘,但希望的曙光已然穿透云层。随着科技的持续进步,它必将在更多未知领域开疆拓土,持续为人类社会的发展赋能。在此,我由衷地鼓励每一位读者,无论你是充满好奇的科技爱好者,还是怀揣梦想的专业探索者,都勇敢地投身于神经网络的学习与研究之中,去挖掘智能的无尽宝藏,共同描绘一个更加智能、美好的未来蓝图。因为在这片充满无限可能的科技星空中,每一个人都有机会成为闪耀的星辰,照亮人类前行的道路。让我们携手共进,迎接智能时代的磅礴浪潮!
发布者:极致前沿,转转请注明出处:https://www.veryin.com/?p=4087