
一、TensorFlow 是什么?


一、TensorFlow 是什么?
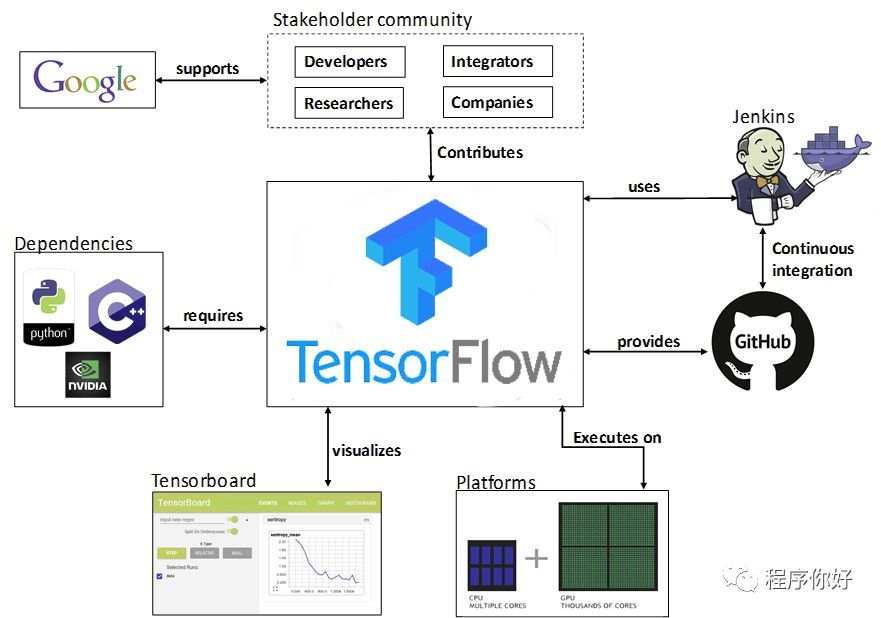
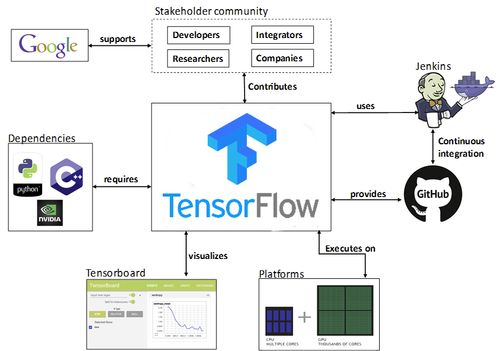
TensorFlow 是由 Google Brain 团队开发的一个开源深度学习框架,于 2015 年发布,并迅速成为深度学习领域最受欢迎的框架之一。它的名字 “TensorFlow” 来源于 “张量”(Tensors)和 “流”(Flow),强调了该框架在数据流图中执行张量运算的能力。从发布以来,TensorFlow 在学术界和工业界都取得了巨大的成功,成为了目前主流的深度学习框架之一。
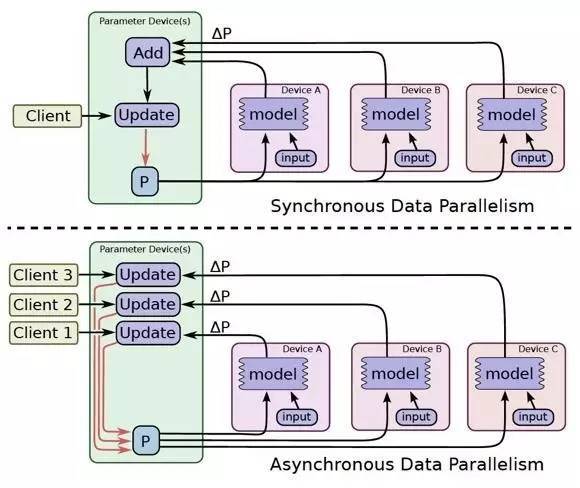
TensorFlow 的核心概念是张量(tensor)和计算图(computational graph)。张量是 TensorFlow 中的基本数据结构,可以看作是多维数组。张量可以包含不同类型的数据,如数字、字符串等,并具有丰富的操作方法。计算图则是 TensorFlow 使用的一种抽象结构,用于描述数据流和操作之间的关系。它由一系列节点(节点表示操作)和边(边表示张量)组成,代表了整个模型的结构。这种图形表示使得 TensorFlow 能够高效地进行分布式计算和自动求导,为深度学习模型的训练和推理提供了强大的支持。
作为深度学习领域的关键工具,TensorFlow 为开发者提供了一个灵活、高效且易用的平台,用于构建和训练各种机器学习模型,特别是深度学习模型。它的出现,极大地推动了人工智能的发展,使得各种复杂的任务,如图像识别、语音识别、自然语言处理等,变得更加容易实现。无论是科研人员探索前沿的 AI 技术,还是企业开发者为产品添加智能功能,TensorFlow 都提供了丰富的资源和强大的功能,助力他们实现目标。
二、TensorFlow 的显著优势

(一)高度的灵活性
TensorFlow 不是一个严格的 “神经网络” 库,只要你可以将你的计算表示为一个数据流图,就可以使用它。用户可以基于 TensorFlow 的基础上用 Python 编写自己的上层结构和库,如果 TensorFlow 没有提供我们需要的 API,也可以自己编写底层的 C++ 代码,通过自定义操作将新编写的功能添加到 TensorFlow 中。定义顺手好用的新复合操作和写一个 Python 函数一样容易,而且也不用担心性能损耗。当然万一找不到想要的底层数据操作,也可以自己写一点 C++ 代码来丰富底层操作。
(二)出色的跨平台性
TensorFlow 可以在多种硬件和操作系统上运行,包括 CPU、GPU 和 TPU(Tensor Processing Unit),以及 Windows、Linux、macOS 等操作系统,甚至还能部署在移动设备、Web 浏览器和边缘设备上,适用于多种应用场景。无论是在台式机上进行深度学习的训练,还是想把模型在多个 CPU 上规模化运算,亦或是将训练好的模型放到移动设备上运行,TensorFlow 都可以轻松实现,无需大量修改代码。
(三)强大的多语言支持
TensorFlow 提供了 Python、C++、Java、JavaScript、Go 和 Swift 等多种语言的 API,使得开发者可以在不同环境和需求下使用同一个框架。其中,Python API 最为成熟和广泛使用,它利用 Python 简洁的语法,提供了一个相对容易上手的机器学习库,对于快速原型开发和实验至关重要。而 C++ API 则使得在性能敏感的应用场合下,开发人员可以更好地管理内存和执行速度;Java API 适用于在 Java 平台上开发和运行 TensorFlow 模型,能方便地与其他 Java 库和框架集成;Go API 支持开发人员利用 Go 语言简洁且并发性强的特点构建高效的网络服务和分布式系统。未来,TensorFlow 还计划支持更多流行的语言,以满足不同开发者的需求。
(四)丰富的工具和库
TensorFlow 提供了一系列强大的工具来简化开发过程,如 TensorBoard 用于可视化训练过程,它可以帮助开发者直观地了解模型的训练情况,包括损失函数的变化、准确率的提升等,以便及时调整模型参数;TensorFlow Hub 用于共享预训练模型,开发者可以直接使用这些经过大量数据训练的模型,在此基础上进行微调,快速应用到自己的项目中,节省大量的训练时间;TensorFlow Lite 用于移动和嵌入式设备,能够将模型进行优化和压缩,使其可以在资源受限的移动端高效运行,为开发智能移动应用提供了便利。此外,还有 TensorFlow Serving 用于模型部署,TensorFlow.js 用于在浏览器中运行等,这些工具覆盖了从模型开发、训练到部署的各个环节,全方位助力开发者。
三、应用领域广泛
(一)计算机视觉
在计算机视觉领域,TensorFlow 展现出了卓越的性能,助力诸多复杂任务的实现。以图像分类为例,借助 TensorFlow 的卷积神经网络(CNN),能够对图像中的物体进行精准分类。像在 MNIST 手写数字数据集上,通过构建简单的 CNN 模型,可以轻松识别出手写数字;而在 CIFAR-10 或 ImageNet 等更为复杂的数据集上,利用更深层次的 CNN 架构,如 ResNet、VGG 等模型,能够准确区分出飞机、汽车、鸟类等各种不同类别的物体。目标检测方面,TensorFlow 支持如 SSD(Single Shot MultiBox Detector)和 Faster R-CNN 等先进算法,这些算法可以在图像中快速定位并识别出多个对象,同时给出每个对象的类别和边界框,无论是在安防监控中检测行人、车辆,还是在工业质检里识别产品缺陷,都发挥着关键作用。人脸识别也是 TensorFlow 的拿手好戏,基于其搭建的人脸识别系统,广泛应用于门禁系统、考勤打卡以及安防追踪等场景,通过对人脸特征的提取与比对,实现精准的身份识别。
(二)自然语言处理
自然语言处理是 TensorFlow 的另一个重要应用战场。在语言模型构建上,它支持从基础的循环神经网络(RNN)到长短期记忆网络(LSTM)、门控循环单元(GRU),再到如今最前沿的 Transformer 架构等多种模型。以文本生成为例,利用 LSTM 或 GRU 模型,能够根据给定的前文,生成连贯、通顺的后续文本,可用于创作故事、诗歌等创意性内容;而基于 Transformer 的 GPT 系列模型,更是在大规模文本数据上展现出惊人的语言生成能力,能够模拟人类写作风格,生成高质量文本。在机器翻译领域,TensorFlow 助力实现了诸如谷歌翻译等强大的翻译工具,通过对海量的平行语料库进行学习,模型能够快速准确地将一种语言翻译为另一种语言,打破语言隔阂,促进全球交流。情感分析方面,借助 TensorFlow 构建的深度学习模型,可以对社交媒体评论、产品评价等文本进行情感倾向判断,帮助企业了解用户反馈,及时调整产品策略。
(三)语音识别
TensorFlow 在语音识别领域同样有着出色表现,推动了智能语音交互技术的蓬勃发展。利用卷积神经网络(CNN)、长短时记忆网络(LSTM)及其变体等深度学习模型,能够构建出高精度的语音识别系统。例如,通过对大量的语音样本进行学习,模型可以准确地将语音信号转换为对应的文本信息。像智能语音助手,如苹果的 Siri、亚马逊的 Alexa 以及国内的小爱同学等,背后都离不开 TensorFlow 的支持,它们能够理解用户的语音指令,执行诸如播放音乐、查询天气、设置闹钟等各种任务,为人们的生活带来极大便利。在客服领域,语音识别技术结合自然语言处理,实现了智能客服自动接听电话、解答客户问题,大大提高了服务效率。
(四)推荐系统
在当今信息爆炸的时代,推荐系统成为各大平台吸引用户、提升留存的关键技术,而 TensorFlow 为推荐系统的构建提供了强有力的支持。无论是电商平台、内容平台还是社交媒体平台,都广泛应用 TensorFlow 搭建推荐模型。以电商为例,通过对用户的浏览历史、购买记录等行为数据进行分析,利用协同过滤、基于内容的推荐或混合推荐等算法,构建用户兴趣模型,进而为用户精准推荐可能感兴趣的商品,提高购买转化率。在内容平台如抖音、今日头条等,TensorFlow 助力实现个性化的内容推荐,根据用户的观看习惯、点赞评论等行为,推送符合用户口味的视频、文章等内容,让用户沉浸其中。社交媒体平台则借助推荐系统,为用户推荐可能认识的好友、感兴趣的群组以及热门话题,增强用户粘性与活跃度。
四、快速上手教程
(一)安装 TensorFlow
安装 TensorFlow 的过程因操作系统和硬件配置而异,以下是在不同平台上安装的详细步骤:
Windows 系统:
- CPU 版本:首先,确保你的系统已经安装了 Python,建议使用 Python 3.6 及以上版本。打开命令提示符(CMD),输入以下命令:
pip install tensorflow这将会使用 pip 工具从 Python 官方源下载并安装 TensorFlow 的 CPU 版本。安装过程可能需要一些时间,取决于你的网络速度。安装完成后,可以在 Python 环境中导入 TensorFlow 来验证安装是否成功:
import tensorflow as tf- GPU 版本:如果你拥有 NVIDIA GPU,想要利用其进行加速计算,安装过程会稍微复杂一些。首先,需要确保你的显卡驱动是最新版本,可以通过 NVIDIA 官方网站下载并安装。接着,安装 CUDA Toolkit,这是 NVIDIA 推出的用于 GPU 编程的开发工具包,TensorFlow GPU 版本依赖于此。访问 CUDA 官方网站,根据你的显卡型号和操作系统版本选择合适的 CUDA 版本进行下载安装。安装完成后,还需要安装 cuDNN(CUDA Deep Neural Network library),它是针对深度神经网络的 GPU 加速库,能够大幅提升 TensorFlow 在 GPU 上的运行效率。同样在 NVIDIA 官网下载对应版本的 cuDNN,并按照官方文档进行配置。最后,使用以下命令安装 TensorFlow GPU 版本:
pip install tensorflow-gpuLinux 系统:
- CPU 版本:对于大多数 Linux 发行版,如 Ubuntu、Debian 等,安装过程与 Windows 类似。打开终端,确保已经安装了 Python 3 和 pip,然后执行:
pip install tensorflow如果遇到权限问题,可以在命令前加上sudo。
- GPU 版本:以 Ubuntu 为例,首先更新系统软件包:
sudo apt-get update
sudo apt-get upgrade接着安装 NVIDIA 显卡驱动,可以使用ubuntu-drivers devices命令查看推荐的驱动版本,然后使用sudo apt-get install进行安装。安装完成后,安装 CUDA 和 cuDNN,步骤与 Windows 下类似,需要注意版本的兼容性。最后通过 pip 安装 TensorFlow GPU 版本:
pip install tensorflow-gpumacOS 系统:
- CPU 版本:Mac 系统自带了 Python,打开终端后,直接执行:
pip install tensorflow就可以安装 TensorFlow 的 CPU 版本。需要注意的是,Mac 系统上的 GPU 加速支持相对有限,因为 NVIDIA GPU 在 Mac 上的驱动支持不够完善。如果想要在 Mac 上使用 GPU 加速,可以考虑使用 Google Colab 等云端平台。
无论在哪个平台上安装,安装完成后都建议运行一些简单的 TensorFlow 代码来验证安装是否成功,确保后续开发顺利进行。同时,关注 TensorFlow 官方文档,以获取最新的安装指南和版本兼容性信息,避免因版本问题导致的错误。
(二)导入相关库
在 Python 脚本或 Jupyter Notebook 中,使用以下代码导入 TensorFlow 及常用的辅助库:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt这里,numpy是一个强大的数值计算库,在数据处理和矩阵运算方面非常高效,TensorFlow 与之配合默契,常用于数据预处理和模型输入数据的准备。matplotlib.pyplot则是用于数据可视化的库,能够将模型训练过程中的数据,如损失值的变化、准确率的提升等以图表的形式展示出来,让我们直观地了解模型的训练情况,方便调试和优化模型。
(三)加载数据集
以经典的 Fashion MNIST 数据集为例,TensorFlow 提供了便捷的方法来加载内置数据集:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()这几行代码就能轻松地将 Fashion MNIST 数据集下载并拆分为训练集和测试集,其中训练集包含 60,000 张 28×28 像素的灰度衣物图像,测试集包含 10,000 张。图像数据以numpy.ndarray的形式存储,标签则是对应的衣物类别索引(0 – 9),分别对应 T 恤、裤子、套头衫等 10 个类别。
如果要加载自定义数据集,例如你自己收集的图像数据集,首先需要将数据集整理成合适的结构,通常可以按照类别将图像存放在不同的文件夹下。然后使用tf.keras.preprocessing.image.ImageDataGenerator类来进行数据加载和预处理,它提供了诸如图像缩放、归一化、数据增强(随机翻转、旋转等)等功能,示例代码如下:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory('train_data_dir',
target_size=(28, 28),
batch_size=32,
class_mode='categorical')
test_generator = test_datagen.flow_from_directory('test_data_dir',
target_size=(28, 28),
batch_size=32,
class_mode='categorical')这里假设你的训练集图像存放在train_data_dir文件夹下,测试集图像存放在test_data_dir文件夹下,每个文件夹下按照类别分设子文件夹。通过这样的设置,就能利用ImageDataGenerator高效地加载自定义数据集,并在训练过程中对数据进行实时处理,提高模型的泛化能力。
(四)构建模型
使用 TensorFlow 的Sequential API 可以快速构建一个简单的神经网络模型,以下是一个基本的示例:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])这段代码构建了一个包含三个层的神经网络:首先,Flatten层将输入的 28×28 像素的二维图像数据展平为一维向量,作为后续全连接层的输入;接着,一个具有 128 个神经元的全连接隐藏层,使用 ReLU(Rectified Linear Unit)作为激活函数,它能够为模型引入非线性特性,增强模型的表达能力;最后,输出层有 10 个神经元,对应 Fashion MNIST 数据集中的 10 个类别,使用softmax激活函数将神经元输出转换为类别概率分布,使得模型能够输出每个类别的预测概率。
在构建模型时,还可以根据需求调整各层的参数,如隐藏层的神经元数量、激活函数的类型等。神经元数量越多,模型的学习能力越强,但也可能导致过拟合;不同的激活函数适用于不同的场景,除了 ReLU 和softmax,还有sigmoid、tanh等可供选择,需要根据实际任务进行权衡。
(五)编译模型
在训练模型之前,需要对模型进行编译,指定优化器、损失函数和评估指标:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])这里选择了adam优化器,它是一种自适应学习率的优化算法,基于随机梯度下降,能够在训练过程中自动调整学习率,使得模型更快更稳定地收敛。损失函数选用sparse_categorical_crossentropy,适用于多分类任务且标签为整数形式的情况,它衡量了模型预测结果与真实标签之间的差异程度,模型训练的目标就是最小化这个损失函数。评估指标选择了accuracy,即准确率,它直观地反映了模型在训练集或测试集上预测正确的样本比例,方便我们了解模型的性能表现。
对于不同的任务,这些参数的选择会有所不同。例如,在回归任务中,损失函数通常会选择均方误差(mean_squared_error)等;评估指标还可以根据需求添加如均方根误差(root_mean_squared_error)等。优化器除了adam,还有sgd(随机梯度下降)、Adagrad、Adadelta等,它们各自有不同的特点和适用场景,需要根据模型的特点和数据集的情况进行调整。
(六)训练模型
使用编译好的模型和训练数据,通过以下代码进行模型训练:
model.fit(train_images, train_labels, epochs=10, batch_size=32)这里train_images和train_labels是之前加载的训练集数据,epochs表示训练的轮数,即模型完整遍历训练集的次数,每一轮模型都会根据数据进行参数更新;batch_size则指定了每次更新参数时使用的样本数量,较小的batch_size会使得模型更新更加频繁,但训练时间可能会变长,较大的batch_size可以加快训练速度,但可能会导致收敛不稳定。
在训练过程中,模型会输出每一轮的训练损失和准确率,通过观察这些指标的变化,我们可以了解模型的学习进度。如果损失值持续下降,准确率持续上升,说明模型正在不断优化;如果出现损失值不再下降甚至上升的情况,可能需要调整模型的参数,如学习率、层数、神经元数量等,或者检查数据是否存在问题。
(七)评估模型
模型训练完成后,使用测试集来评估模型的性能:
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')evaluate方法会返回测试集上的损失值和准确率,通过比较测试准确率与训练准确率,以及观察测试损失值的大小,可以判断模型是否出现过拟合或欠拟合的情况。如果测试准确率远低于训练准确率,可能意味着模型过拟合,对训练数据过度学习,而缺乏对新数据的泛化能力;如果测试准确率和训练准确率都较低,可能是模型欠拟合,没有充分学习到数据的特征,需要进一步优化模型结构或调整训练参数。
以上就是 TensorFlow 的快速上手教程,通过这些基本步骤,你可以搭建并训练自己的深度学习模型,解决各种实际问题。随着对 TensorFlow 的深入学习,你还可以探索更多高级功能和优化技巧,提升模型的性能。
五、实际案例展示

(一)图像分类案例
以识别花卉种类为例,我们使用 TensorFlow 构建一个图像分类模型。数据集选用公开的花卉照片数据集,包含雏菊、玫瑰、郁金香等五类花卉,共约 3670 张图像。
首先进行数据预处理,利用tf.keras.preprocessing.image.ImageDataGenerator对图像进行归一化、随机缩放、翻转等增强操作,将数据集按 8:2 的比例划分为训练集和测试集。
模型构建上,采用卷积神经网络(CNN)架构,包含多个卷积层、池化层与全连接层。如使用Conv2D层提取图像特征,搭配MaxPooling2D层进行下采样,以减少计算量并保留关键特征;全连接层Dense用于分类预测,激活函数选用 ReLU 和 softmax。
编译模型时,选择 Adam 优化器与categorical_crossentropy损失函数,监控准确率指标。训练过程设置 10 个轮次(epochs),批次大小为 32。训练期间,借助 TensorBoard 可视化工具,实时观察损失值与准确率的变化曲线,依据曲线调整模型参数,如学习率、卷积核数量等。
经训练与调优,模型在测试集上的准确率可达 85% 左右,能够较为准确地识别不同种类的花卉图像,为植物识别类应用提供了有效的技术支持。
(二)文本情感分析案例
对于社交媒体评论的情感分析任务,我们使用 TensorFlow 搭建模型。数据集收集自某社交平台的电影评论,包含积极与消极两类情感标签,共约 50000 条文本数据。
文本预处理阶段,先通过结巴分词工具对中文文本分词,去除停用词,再利用词袋模型或 TF-IDF 方法将文本转化为向量表示。
模型选用循环神经网络(RNN)及其变体长短期记忆网络(LSTM),以捕捉文本序列中的语义依赖关系。构建Sequential模型,嵌入层Embedding将单词索引映射为向量,LSTM 层处理序列信息,全连接层输出情感分类结果,激活函数采用 sigmoid。
编译模型选用 Adam 优化器与binary_crossentropy损失函数,关注准确率指标。训练时设置合适的轮次与批次大小,同样利用 TensorBoard 跟踪训练过程,查看模型在训练集与验证集上的损失、准确率变化。
经多次调优,模型在测试集上的准确率可达 80% 上下,能有效判断评论的情感倾向,助力企业了解用户对产品、电影等的反馈,为市场调研、舆情监测提供帮助。
通过这些实际案例,希望能为大家在运用 TensorFlow 解决实际问题时提供清晰的思路与实践参考,鼓励大家动手尝试,挖掘 TensorFlow 的更多潜力,创造出更多有价值的应用。
六、常见问题解答
(一)安装相关问题
- 问题:在 Windows 系统下使用 pip 安装 TensorFlow 时,出现 “Could not find a version that satisfies the requirement tensorflow” 错误。
- 解决方法:这通常是由于网络问题导致无法连接到 Python 官方源,或是源中没有对应的 TensorFlow 版本。可以尝试更换国内的镜像源,如使用清华大学的镜像源,在命令行中输入:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow若依然报错,检查 Python 版本是否符合要求,TensorFlow 2.x 通常支持 Python 3.7 – 3.11,确保已安装对应版本的 Python。
- 问题:安装 GPU 版本的 TensorFlow 后,运行代码时提示 “Could not find ‘cudart64_90.dll’”。
- 解决方法:这意味着系统找不到所需的 CUDA 动态链接库。首先要确保已正确安装 CUDA Toolkit,并且版本与 TensorFlow 适配。例如,TensorFlow 2.5 一般适配 CUDA 11.2。如果已安装正确版本但仍报错,需要将 CUDA 的安装路径添加到系统环境变量PATH中,找到 CUDA 的安装目录(如C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin),将其添加到PATH,然后重启命令行或开发环境。
(二)运行相关问题
- 问题:在 Python 脚本中导入 TensorFlow 时,出现 “AttributeError: module ‘tensorflow’ has no attribute ‘placeholder’” 错误。
- 解决方法:这是因为在 TensorFlow 2.x 版本中,placeholder已被移除或更改了使用方式。如果是从 TensorFlow 1.x 代码迁移过来,可在代码开头添加:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()这样可以在一定程度上兼容旧版本的代码写法,但建议逐渐过渡到 TensorFlow 2.x 的新特性,如使用tf.function替代placeholder等。
- 问题:运行 TensorFlow 代码时,GPU 利用率很低,模型训练速度没有明显提升。
- 解决方法:首先,确保安装了与 GPU 适配的 CUDA 和 cuDNN 版本,并且 TensorFlow 正确识别到 GPU。可以在代码中添加:
physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices)来检查 GPU 是否被识别。若已识别,尝试减小batch_size,因为过大的batch_size可能导致 GPU 在等待数据传输时闲置,适当减小能让 GPU 更充分地工作;还可以检查模型代码,是否存在一些 CPU 密集型的操作无意中限制了整体速度,例如数据预处理部分是否可以进一步优化,移到 GPU 上运行等。
(三)模型训练相关问题
- 问题:模型在训练过程中出现过拟合,训练准确率很高,但测试准确率远低于训练准确率。
- 解决方法:过拟合意味着模型对训练数据学习过度,而泛化能力较差。可以采用以下几种方法应对:一是增加数据集的规模,收集更多的数据进行训练,让模型学习到更广泛的特征模式;二是使用数据增强技术,如在图像数据训练中,对图像进行随机裁剪、旋转、翻转等操作,扩充数据集的多样性;三是在模型中添加正则化项,如 L1、L2 正则化,约束模型参数,防止过拟合,在tf.keras模型中,可以通过在层定义时添加kernel_regularizer参数来实现,例如:
model.add(tf.keras.layers.Dense(64, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.01)))- 问题:模型训练时损失值不下降,准确率也不提升,陷入停滞。
- 解决方法:这可能是由于学习率设置不合理导致的。学习率过大,模型在训练时会跳过最优解,导致无法收敛;学习率过小,模型收敛速度极慢,甚至看起来像是停滞。可以尝试调整学习率,使用学习率衰减策略,如在tf.keras中使用tf.keras.optimizers.schedules.ExponentialDecay,随着训练轮数的增加逐渐减小学习率:
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.01,
decay_steps=10000,
decay_rate=0.9)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)也可以检查模型结构是否过于简单或复杂,对于简单的数据,复杂模型可能会导致过拟合从而使训练停滞,而对于复杂数据,简单模型可能无法学习到足够的特征,需要适当调整模型的层数、神经元数量等参数。
七、总结与展望
通过本文,我们深入了解了 TensorFlow 这一强大的深度学习框架。从其核心概念、显著优势,到广泛的应用领域、快速上手教程,再到实际案例展示和常见问题解答,希望为大家呈现了一个全面且实用的 TensorFlow 指南。
TensorFlow 作为深度学习领域的中流砥柱,持续推动着人工智能技术的边界。然而,技术的发展永无止境。未来,在模型可解释性方面,我们期待 TensorFlow 能提供更多工具,帮助开发者揭开模型 “黑箱”,让深度学习的决策过程更加透明,增强公众对 AI 技术的信任;在高效的轻量化模型方向,随着边缘计算的普及,TensorFlow Lite 等技术将进一步优化,通过更先进的模型剪枝、量化和知识蒸馏手段,使模型在资源受限的设备上也能展现强大性能;强化学习与自监督学习的融合也是重要趋势,TensorFlow 有望为这种复杂学习范式提供更完善的支持,开启更多创新应用场景;自动化深度学习(AutoML)领域,TensorFlow AutoML 等工具将持续进化,让非专业人士也能轻松构建高效模型,加速 AI 技术的落地普及。
深度学习与 TensorFlow 的未来充满无限可能,持续关注并深入学习这些前沿技术,将助力我们在这个智能时代中抢占先机,解决更多现实挑战,创造更多价值。愿大家在 TensorFlow 的学习与应用之路上不断探索,收获满满!
发布者:极致前沿,转转请注明出处:https://www.veryin.com/?p=4147